By
Sep 25, 2023Adamos Loizou

Adamos Loizou
We like to reduce the most mundane, complex and time-consuming work associated with managing a Kafka platform. One such task is backing up topic data.
With a growing reliance on Kafka for various workloads, having a solid backup strategy is not just a nice-to-have, but a necessity.
If you haven’t backed up your Kafka and you live in fear of disaster striking, worry no more. With Lenses Stream Reactor for Amazon S3, we've launched an intuitive feature to back up and restore all your topics effortlessly. This not only simplifies governance but also boosts confidence in onboarding Kafka applications, potentially saving costs and revealing new data use cases.
Here’s a reality check: While Kafka is known for its resilience and data replication capabilities, it's not bulletproof. Some real-world issues that can arise include:
Ransomware attacks
Significant outages
Incorrect topic data retention changes or deletions
Influx of corrupted data
Sure, there may be times when upstream systems could resend their data, but having your own backup can simplify the recovery process.
When looking at backup strategies for Kafka, one solution doesn't fit every situation. Here's a breakdown of the usual approaches:
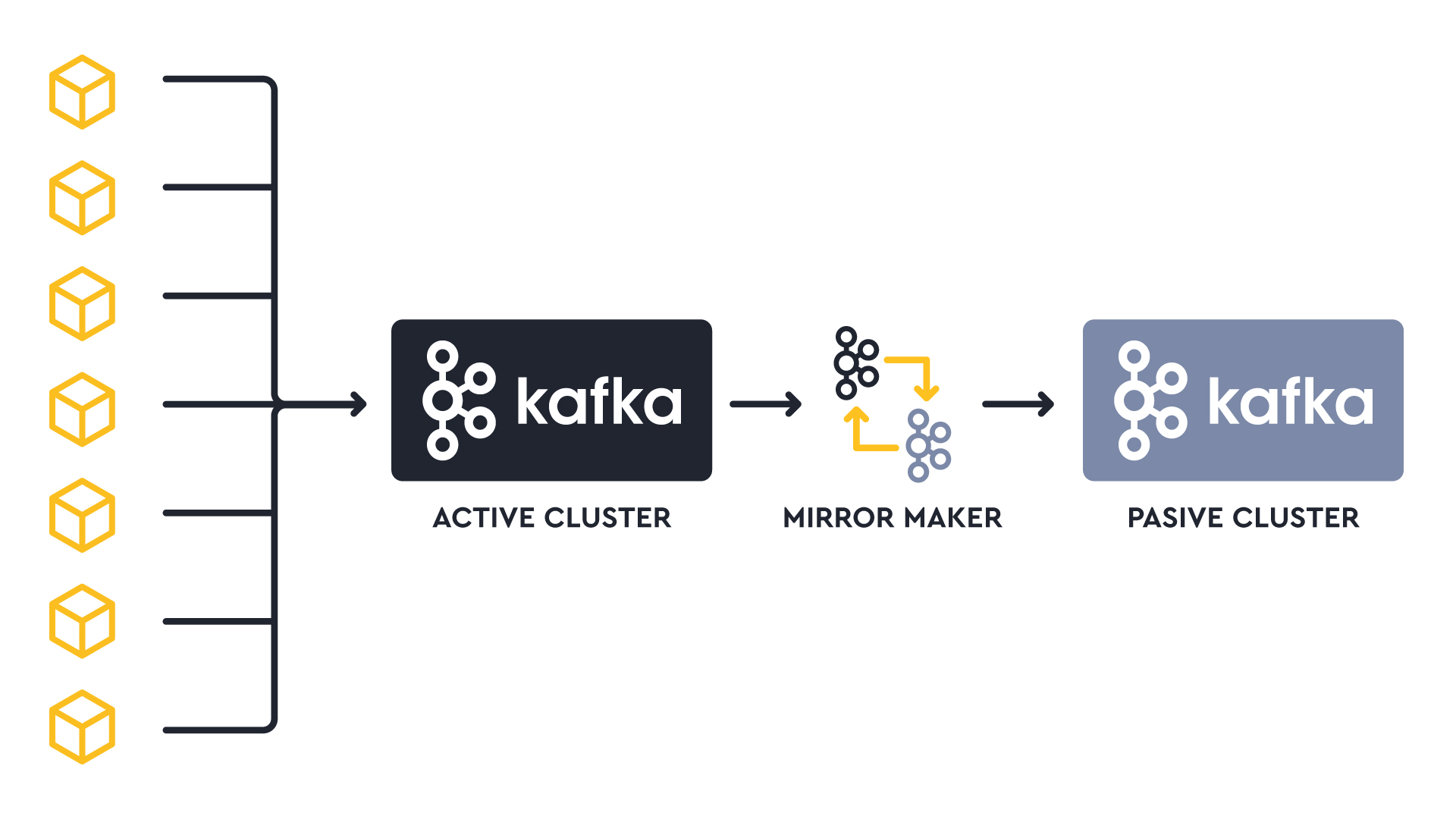
This method involves duplicating data to a separate Kafka cluster, acting as a backup. While tools like Mirror Maker 2 or Confluent Replicator are effective, having a passive cluster can be expensive.
This method involves your storage solution snapshotting data at specific intervals. However, it's not foolproof and can result in some data loss.
Using cloud storage, such as Amazon S3 as an external storage for backups provides flexibility.
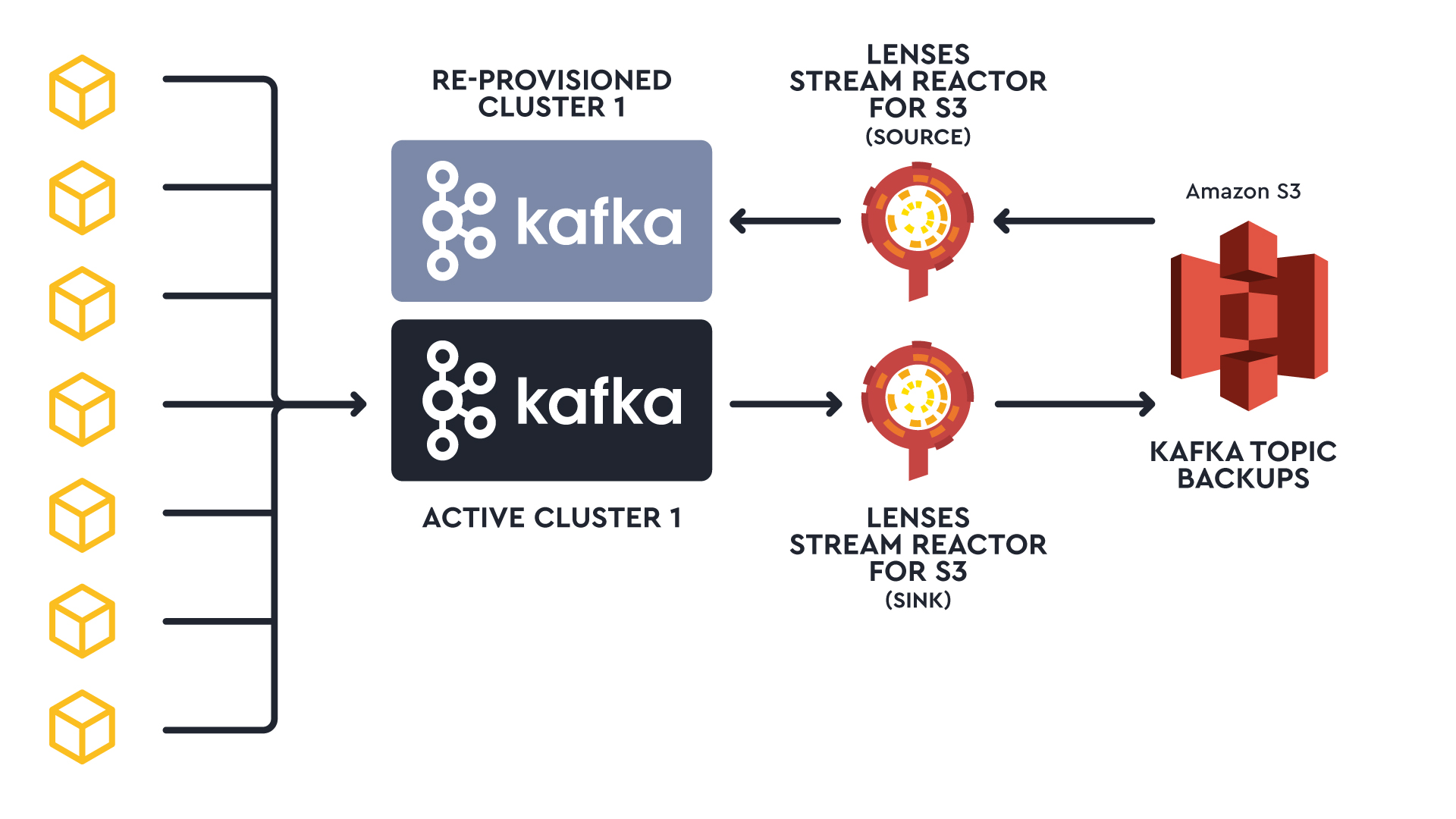
It is this third option that provides a cost-effective and powerful architecture for disaster recovery. No need to have a standby cluster, you can deploy a new AWS MSK cluster on demand and rehydrate the topics from S3.
Amazon S3 is a preferred choice for many reasons. It’s reliable, cost-effective, and offers seamless integration with other AWS services. Moreover, features like Object Versioning and AWS Backup Vault Lock ensure your data can be safeguarded from things such as human error and ransomware attacks.
Lenses offers an Apache 2 licensed source-and-sink S3 Connector to streamline the backup and restore process for Kafka topics.
Those familiar with Kafka Connect know its complex intricacies. You need to correctly configure the correct serialization, SMTs and dozens of other settings. As your production topics grow in number, configuring connectors in this way isn’t scalable. You need a more well-governed backup and restore process.
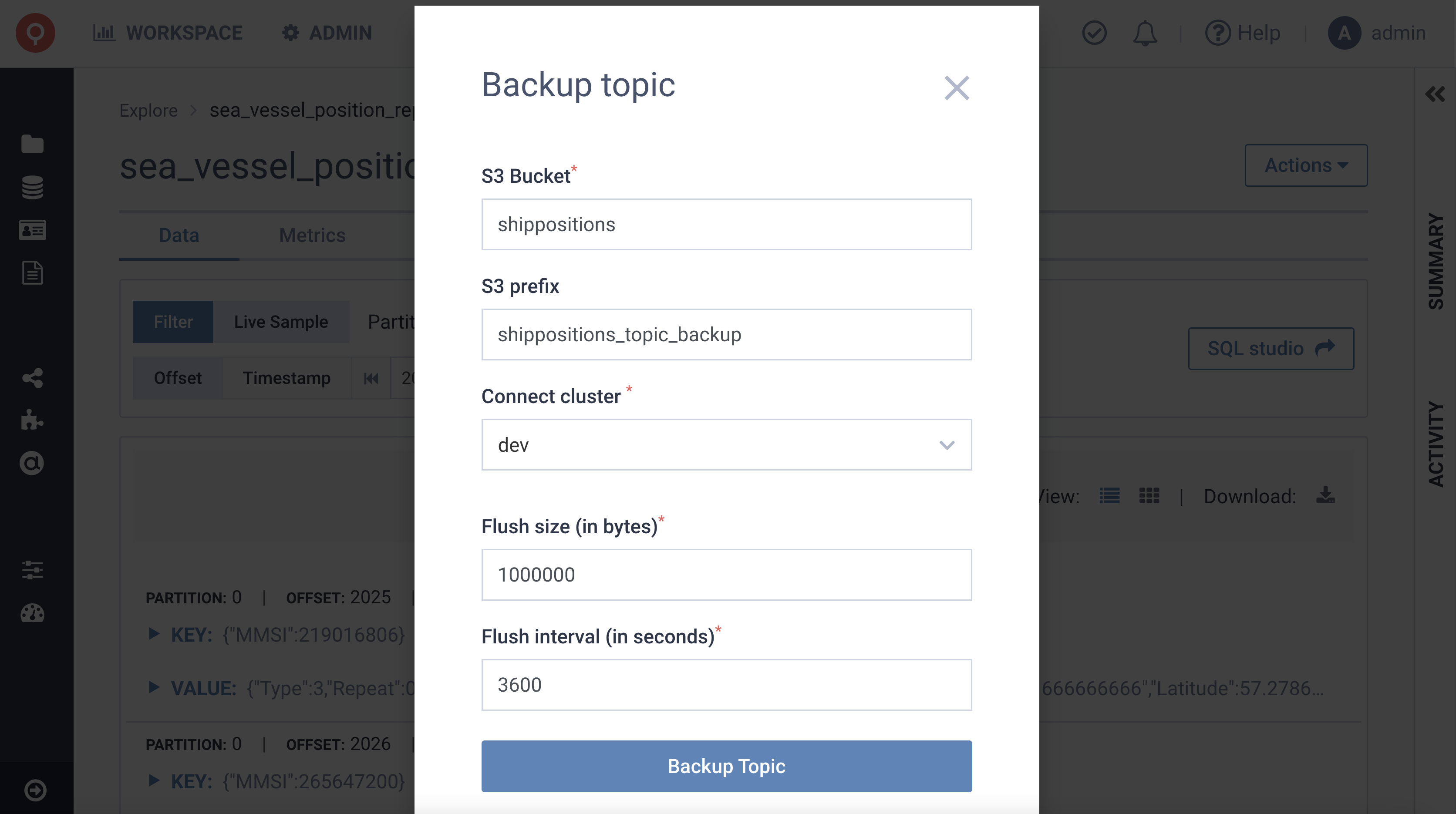
Now, with Lenses 5.3, Lenses provides a UI experience, protected with role-based security and auditing, to deploy connectors on your Kafka Connect infrastructure specifically for backup/restore with just a few clicks.
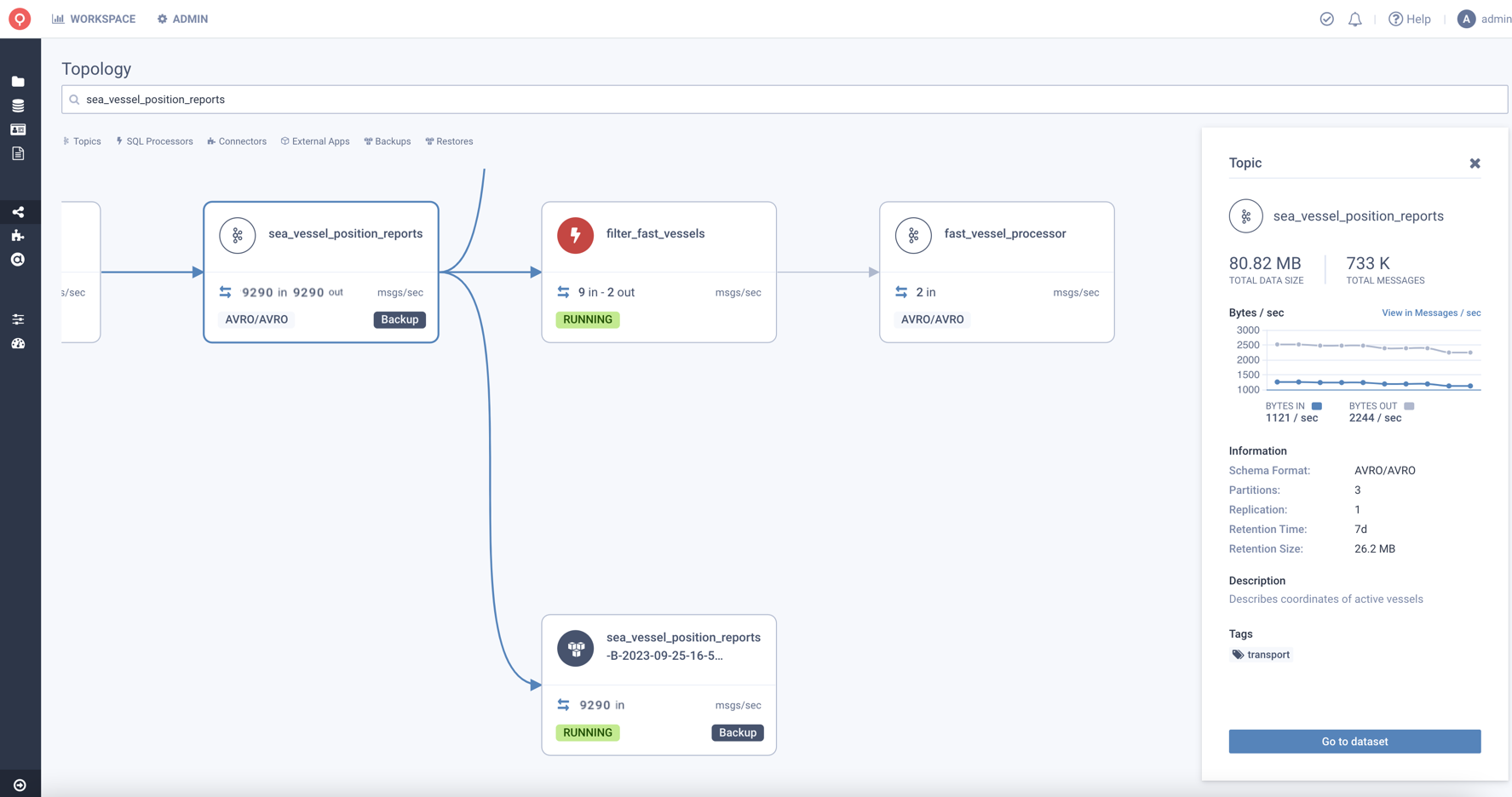
The deployed S3 Connector will automatically be monitored, mapped & governed like any other connector in Lenses.
To understand how it works, we need to explain how Lenses stores the data in S3.
A Kafka message consists of several components: the key, the value, headers, and metadata such as the topic, partition, offset, and timestamp.
The newest S3 Connector wraps the Kafka message in an "envelope", streamlining backup and restore without relying heavily on Kafka Connect Single Message Transformation.
The envelope is structured as follows:
In this format, the entire Kafka message is kept intact. The Connector uses this to rebuild and send the message to its target topic. Data can be restored to any topic or cluster, maintaining event sequence. But even with the original offset in the envelope, it can't be adjusted or reused in a different topic.
____
____
Your topic data in S3 isn't just for Kafka restores via Lenses.
You can also use this S3-stored data for other tasks, like analytics with AWS Athena, AWS Glue, Redshift, Snowflake, or even powering event-driven apps and Large Language Models (LLM).
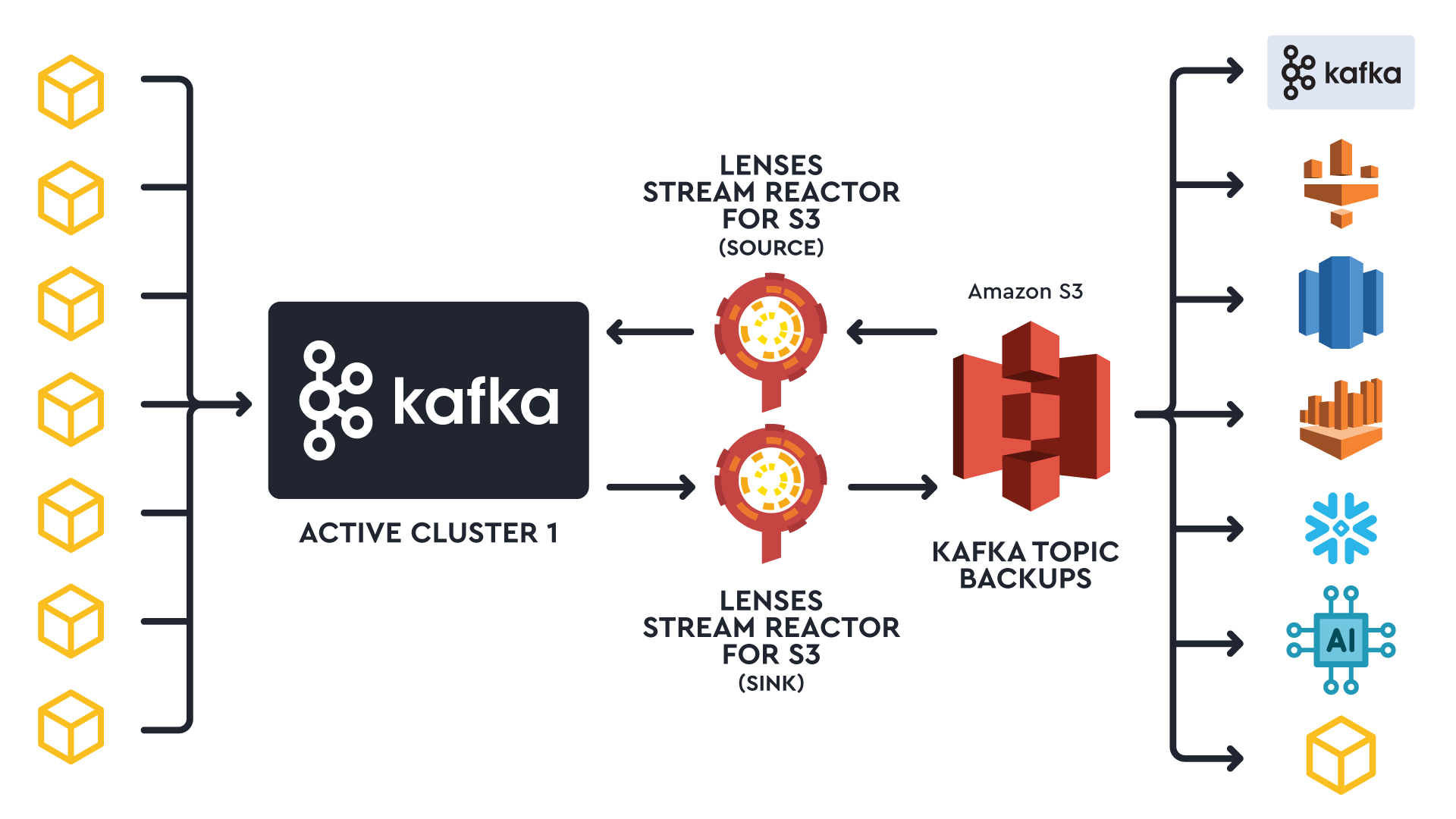
How quickly does the data land in S3? It hinges on the connector's flush policy, set by conditions like time, object size, or message count. Lenses has a default setting, but you can tweak it if needed.
Backing up data offers more than you think.
When you sink topic backup data to S3, another connector can stream those events to a different active cluster. Given that data is saved to S3 during flushes, this setup works well if you're sharing data between active clusters and don't need instant updates on the second cluster.
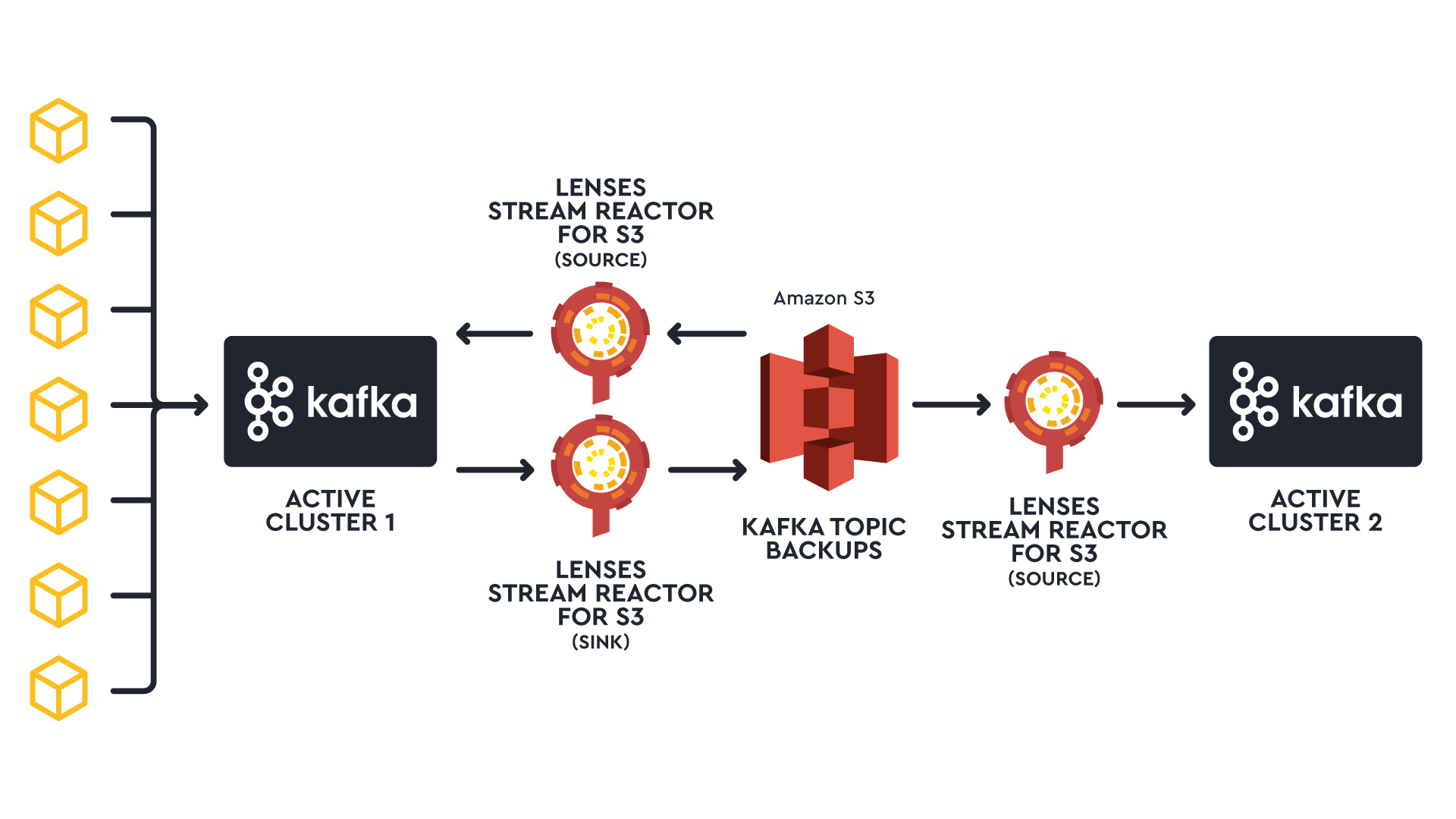
Learn more about our Kafka to S3 connector and what other use cases it can solve.





